이전 글
Kaggle Courses - Model Validation
Experimenting With Different Models
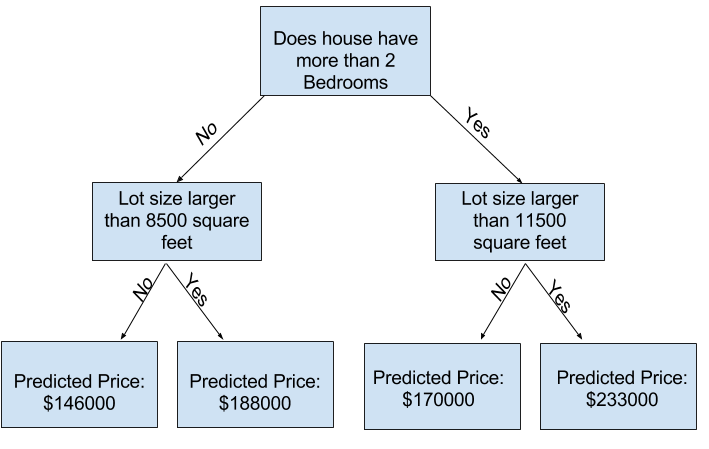
만약 어떤 집에 대한 데이터를 트리로 나눈다고 했을 때, 집을 여러 리프로 나누면 각 리프에 있는 집의 수도 줄어든다. 집이 거의 없는 리프는 실제값과 유사하게 예측을 할 수 있지만, 각 예측은 몇 개의 집만을 기반으로 하기에, 새로운 데이터에 대한 예측을 신뢰할 수 없게 된다.
이를 Overfitting(과대적합)이라고 한다. 모델이 학습 데이터와 거의 완벽하게 일치하지만 검증 및 기타 새로운 데이터에서는 제대로 작동하지 않는다.
반대로 트리를 매우 얕게 만들면 집을 매우 뚜렷한 그룹으로 나누지 않는다.
극단적으로, 트리가 집을 2개 혹은 4개로만 나누면 각 그룹은 여전히 다양한 종류의 집을 가지고 있을 것이고, 결과적으로 예측은 굉장히 동떨어져 있을 것이다.
이처럼 모델이 데이터의 중요한 차이점이나 패턴을 파악못해 훈련 데이터에서의 성능이 떨어지는 것을 Underfiiting(과소적합)이라고 한다.
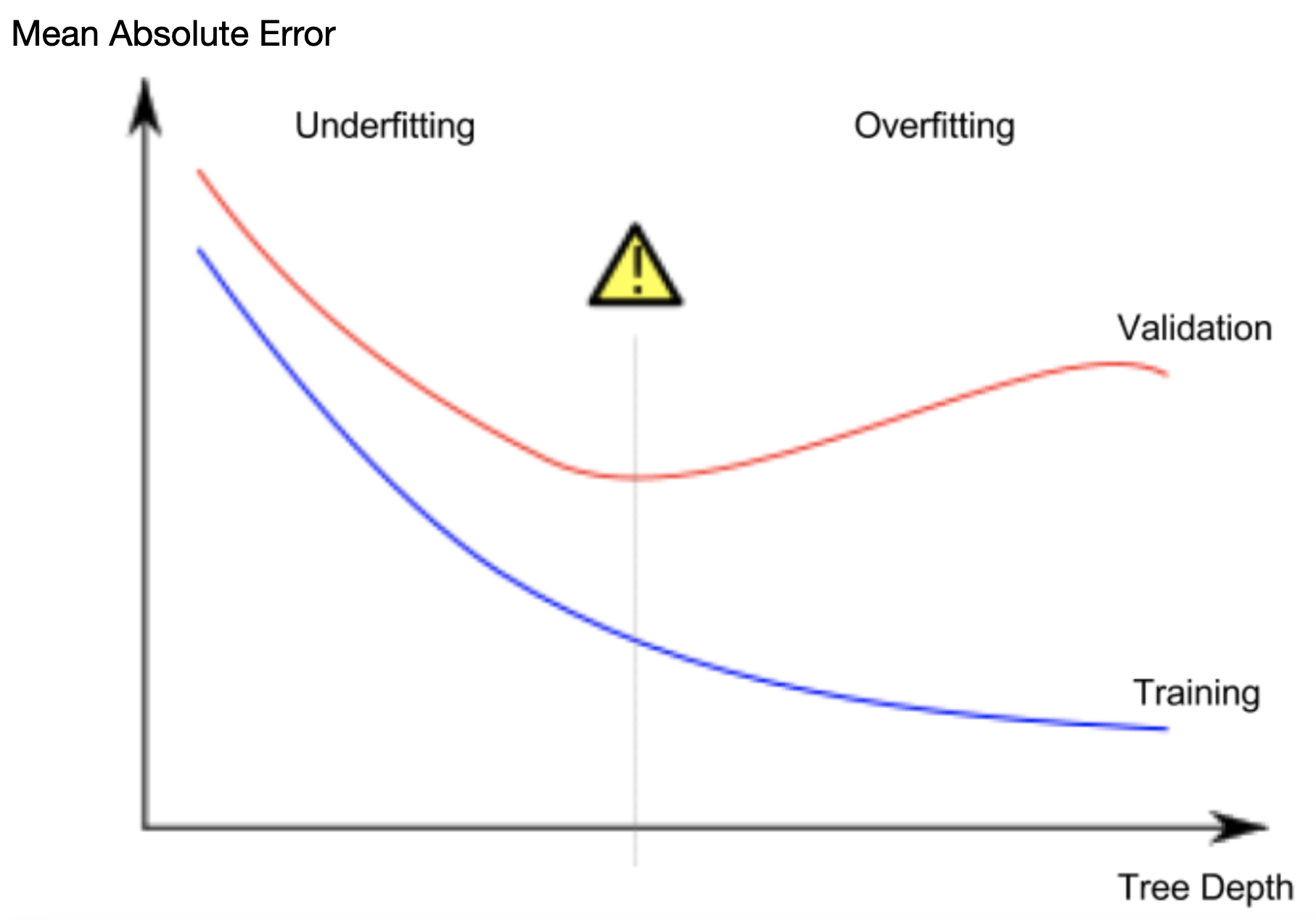
과대적합과 과소적합의 스위트 스팟을 찾으려면, 위 그림에서 (빨간색) 검증 곡선의 저점을 찾는다.
Example
트리 깊이를 제어하는 몇 가지 방법이 있다. max_leaf_nodes는 과대적합과 과소적합을 제어하는 방법을 제공한다.
유틸리티 함수를 사용하여 max_leaf_nodes에 대한 다양한 값의 MAE 점수를 비교할 수 있다.
from sklearn.metrics import mean_absolute_error
from sklearn.tree import DecisionTreeRegressor
def get_mae(max_leaf_nodes, train_X, val_X, train_y, val_y):
model = DecisionTreeRegressor(max_leaf_nodes=max_leaf_nodes, random_state=0)
model.fit(train_X, train_y)
preds_val = model.predict(val_X)
mae = mean_absolute_error(val_y, preds_val)
return(mae)
# Data Loading Code Runs At This Point
import pandas as pd
# Load data
melbourne_file_path = '../input/melbourne-housing-snapshot/melb_data.csv'
melbourne_data = pd.read_csv(melbourne_file_path)
# Filter rows with missing values
filtered_melbourne_data = melbourne_data.dropna(axis=0)
# Choose target and features
y = filtered_melbourne_data.Price
melbourne_features = ['Rooms', 'Bathroom', 'Landsize', 'BuildingArea',
'YearBuilt', 'Lattitude', 'Longtitude']
X = filtered_melbourne_data[melbourne_features]
from sklearn.model_selection import train_test_split
# split data into training and validation data, for both features and target
train_X, val_X, train_y, val_y = train_test_split(X, y,random_state = 0)
for-loop을 사용하여 max_leaf_nodes에 대해 서로 다른 값으로 구축된 모델의 정확도를 비교할 수 있다.]
# compare MAE with differing values of max_leaf_nodes
for max_leaf_nodes in [5, 50, 500, 5000]:
my_mae = get_mae(max_leaf_nodes, train_X, val_X, train_y, val_y)
print("Max leaf nodes: %d \t\t Mean Absolute Error: %d" %(max_leaf_nodes, my_mae))
Max leaf nodes: 5 Mean Absolute Error: 347380
Max leaf nodes: 50 Mean Absolute Error: 258171
Max leaf nodes: 500 Mean Absolute Error: 243495
Max leaf nodes: 5000 Mean Absolute Error: 254983
Conclusion
- Overfitting(과대적합): 미래에 재발하지 않을 가짜 패턴을 포착하여 예측의 정확성이 떨어진다.
- Underfitting(과소적합): 관련 패턴을 포착하지 못해 예측의 정확성이 떨어진다.
모델 학습에는 사용되지 않는 검증 데이터를 사용하여 후보 모델의 정확도를 측정한다. 이를 통해 많은 후보 모델을 시도하고 최상의 모델을 유지할 수 있다.
Exercises
Step 1: Compare Different Tree Sizes
Write a loop that tries the following values for max_leaf_nodes from a set of possible values.
Call the get_mae function on each value of max_leaf_nodes. Store the output in some way that allows you to select the value of max_leaf_nodes that gives the most accurate model on your data.
candidate_max_leaf_nodes = [5, 25, 50, 100, 250, 500]
# Write loop to find the ideal tree size from candidate_max_leaf_nodes
_
# Store the best value of max_leaf_nodes (it will be either 5, 25, 50, 100, 250 or 500)
best_tree_size = ____
# Check your answer
step_1.check()
정답
candidate_max_leaf_nodes = [5, 25, 50, 100, 250, 500]
# Write loop to find the ideal tree size from candidate_max_leaf_nodes
_
# Store the best value of max_leaf_nodes (it will be either 5, 25, 50, 100, 250 or 500)
best_tree_size = 100
# Check your answer
step_1.check()
Step 2: Fit Model Using All Data
You know the best tree size. If you were going to deploy this model in practice, you would make it even more accurate by using all of the data and keeping that tree size. That is, you don’t need to hold out the validation data now that you’ve made all your modeling decisions.
# Fill in argument to make optimal size and uncomment
# final_model = DecisionTreeRegressor(____)
# fit the final model and uncomment the next two lines
# final_model.fit(____, ____)
# Check your answer
step_2.check()
정답
# Fill in argument to make optimal size and uncomment
final_model = DecisionTreeRegressor(max_leaf_nodes=best_tree_size, random_state=1)
# fit the final model and uncomment the next two lines
final_model.fit(X, y)
# Check your answer
step_2.check()